the unbearable bandwidth of being
All media are extensions of some human faculty. The wheel is an extension of the foot. The book is an extension of the eye. The extension of any one sense reshapes how we live — and how we think.
— Marshall McLuhan
your brain processes 10 trillion bits per second. you output 39. the interface is becoming invisible (that was always the goal), nevertheless the bottleneck remains stubbornly human.
say the last thing you ate out loud. the thought you just had took milliseconds to form, and seconds to express. that complex idea you’re trying to convey reading this paragraph thats meta commentating on your compentated is forming via the compression limits of language. when u then go to chat for help by typing it out, it will have only received a trickle when you know you had experience a flood.
this essay is about that constraint: why it exists, how we’ve tried to work around it, and what it means for the future of human-computer interaction. it wont be 125 pages the ai commerce one, but still a good read nonetheless. please give me feedback and disagree otherwise i will ossify into a boomer with bad takes.
the general premise is that as AI agents become our intermediaries with the digital world, the interface we use to communicate intent becomes the critical infrastructure. whoever solves intent translation (getting what’s in your head into the machine) wins.
in classic vincent fashion, we need yet again preface this write up with yet another history lesson. but tbh how we learned to communicate is too nuanced to cover in earnest so lets just do a quick speedrun:
communication history
| Date | Name | Description |
|---|---|---|
| c. 2 million years ago | Primate alarm calls (“grunts”) | Early hominins used instinctive vocalizations to warn of danger, a behavior still observed in modern vervet monkeys. |
| c. 500 thousand years ago | Emergence of speech capacity (FOXP2 gene) | A mutation in the FOXP2 gene—shared by Neanderthals and modern humans—laid the neural groundwork for complex vocalization. |
| c. 285 thousand years ago | Pigment use for symbolic engraving | Red ochre pieces engraved with crosshatches at Olorgesailie, Kenya, indicate early symbolic behavior. |
| c. 100 thousand years ago | Shell-bead personal ornaments | Perforated Nassarius shell beads from Qafzeh Cave, Israel, used for identity and social signaling. |
| c. 77,000 - c. 40,000 BCE | Symbolism in Early Human Culture | This period marks significant developments in human symbolic expression. Around 77,000 BCE, abstract engravings on ochre at Blombos Cave, South Africa, signified the dawn of visual symbolism. By 64,000 BCE, the first figurative cave paintings, including hand-stencils and animal figures, appeared in Sulawesi, Indonesia, representing the oldest known figurative rock art. Approximately 50,000 BCE, the emergence of oral traditions and myths laid the foundation for spoken storytelling, as seen in the continuous Dreamtime narratives of Australian Aboriginal cultures. By 40,000 BCE, portable “Venus” figurines like the Hohle Fels Venus in Germany conveyed shared cultural symbols in a portable form. |
| c. 30 000 BCE - c. 5500 BCE | Pictographs and Proto-Writing | This period marks the evolution of early pictorial and symbolic communication. Sophisticated depictions of animals in Chauvet Cave, France, and vast galleries in Lascaux, France, illustrate advanced pictorial communication. In India, Bhimbetka rock-shelter petroglyphs record communal stories in stone. Jiahu proto-symbols in China represent early attempts at proto-writing, while Mesopotamian clay accounting tokens serve as precursors to abstract record-keeping. |
| c. 3500 BCE - c. 1200 BCE | Early Scripts | This period marks the emergence and development of early writing systems across various civilizations. Proto-cuneiform pictographs on Sumerian tablets from Uruk IV gradually evolved into full writing, leading to the creation of Sumerian cuneiform, the world’s first true writing system, with wedge-shaped impressions on clay tablets in Uruk, Iraq. Simultaneously, Egyptian hieroglyphs emerged as a complex pictographic-ideographic script on early dynastic monuments along the Nile. In South Asia, the Indus Valley script featured undeciphered symbols on seals from Harappa and Mohenjo-Daro, indicating urban communication. In China, the oracle-bone script appeared with inscribed divinatory characters on ox scapulae during the Shang dynasty, representing the earliest form of Chinese writing. |
| c. 1050-600 BCE | Alphabet | The evolution of the alphabet began with the Phoenician alphabet, a streamlined consonant-only script from the Levant, which served as the ancestor to most later alphabets. This was followed by the Greek alphabet around 800 BCE, which adopted Phoenician signs and introduced distinct vowels, enabling full phonetic representation. By 600 BCE, the Aramaic script had spread as the lingua-franca of empires, with Aramaic letters simplifying and uniting diverse peoples in writing. |
| c. 500 BCE - c. 100 BCE | Developments in Grammar | This period saw significant advancements in linguistic codification: Pāṇini’s Aṣṭādhyāyī systematically codified Sanskrit’s phonetics and morphology, marking the earliest linguistic treatise; the Qin dynasty standardized the Chinese script into the small seal script to unify the first Chinese empire; and Dionysius Thrax’s “Art of Grammar” emerged as the first surviving Western grammar, fully codifying the rules of written Greek. |
thanks chatgpt. headpats shoggoth
look at that timeline. from grunts to grammar in 2 million years. then we got from grammar to the internet in 2,500 years. from the internet to LLMs (language generation) in 30 years. the acceleration is powerlawing: each breakthrough removed a bottleneck in information transfer.
im probably not saying anything you don’t already know — it’s a pretty non-controversial thesis. ben thompson of Stratechery has long discussed (and I’m grossly paraphrasing) how history follows a pattern of successive bottleneck-breaking:
- writing removed the bottleneck of memory or location; ideas could persist beyond the speaker’s life.
- duplication: the printing press (1440) meant ideas could spread beyond the capacity of scribes
- distribution: the telegraph (1860s+), then internet, meant ideas could travel at the speed of light
- discovery: search engines (2000s+) meant finding information became tractable at scale
every bottleneck we’ve broken has been about moving information between humans. the bottleneck we haven’t broken (& the one that matters most) is the one between your brain and the world. the interface.
one of the philosophers on my personal mount rushmore, Wittgenstein, argued that the limits of our language are the limits of our world. permit me to reframe it: the limits of our interface are the limits of our world. if the interface constrains language, which constrains thought, which in turn constrains action, then the human-computer interface is the ultimate rate limiter for human potential.
this is important because i want to get into the underutilized opportunities for the future of search and agent interfacing. ill get into that soon but lets just focus on information transfer herein.
language
ah, written language, the foundation of human civilization. we use it every day. look at me, im doing it rn!
written information helped us distribute ideas asynchronously and at scale. we no longer had to be physically present to recieve wisdom. we could even be dead and still mansplain! W. but written information can only convey so much information, and only so fast.
the speed of text
| Metric | Description | Q1 (25th pct) | Median (50th pct) | Q3 (75th pct) |
|---|---|---|---|---|
| Typing speed (computer keyboard) | Average speed for general users, reflecting typical computer usage. | \~35 WPM | 43 WPM | \~51 WPM |
| Typing speed (professional typists) | Speed range for professionals, indicating high proficiency and efficiency. | \~43-80 WPM | 80-95 WPM | \~120+ WPM |
| Stenotype typing speed | Speed using stenotype machines, common in court reporting for rapid input. | \~100-120 WPM | 360 WPM | \~360 WPM |
| Handwriting speed (adult) | Typical speed for adults writing by hand, slower than typing. | \~5-13 WPM | 13 WPM | \~20 WPM |
| Handwriting speed (shorthand) | Speed using shorthand, a method for fast writing by using symbols. | \~350 WPM | 350 WPM | \~350 WPM |
| Morse code speed (manual) | Speed of manual Morse code, used in telecommunication for encoding text. | \~20 WPM | 20 WPM | \~70 WPM |
| Morse code speed (typewriter) | Speed using a typewriter for Morse code, faster than manual transmission. | \~75.6 WPM | 75.6 WPM | \~75.6 WPM |
| Silent reading (non-fiction) | Speed of reading non-fiction silently, reflecting comprehension pace. | \~206 WPM | 238 WPM | \~269 WPM |
| Silent reading (fiction) | Speed of reading fiction silently, often faster due to narrative flow. | \~230 WPM | 260 WPM | \~290 WPM |
| Subvocalization | Slowest reading form, involving internal vocalization of each word. | \~213 WPM | 225 WPM | \~238 WPM |
| Auditory reading | Faster than subvocalization, involves hearing words silently. | \~413 WPM | 425 WPM | \~438 WPM |
| Visual reading | Fastest reading form, recognizing words as visual units without speech. | \~513 WPM | 575 WPM | \~638 WPM |
| Reading aloud (17 languages) | Speed of reading aloud across multiple languages, showing verbal fluency. | \~155-213 WPM | 184 WPM | \~213-257 WPM |
| Audiobook narration speed | Standard speed for narrating audiobooks, balancing clarity and engagement. | \~150-160 WPM | 150-160 WPM | \~150-160 WPM |
| Slide presentation speed | Speed of delivering presentations, ensuring audience comprehension. | \~100-125 WPM | 100-125 WPM | \~100-125 WPM |
| Auctioneer speaking speed | Speed of auctioneers, characterized by rapid speech for bidding processes. | \~250 WPM | 250 WPM | \~250 WPM |
| Fastest speaking (record) | Record speed for speaking, showcasing extreme verbal agility. | \~586-637 WPM | 637 WPM | \~637 WPM |
Sources: WordsRated, Wikipedia, Reading Rate Meta-Analysis
you’d probably agree that there’s obviously gonna be a lot of variance in Words Per Minute (WPM) for each language. some languages are indeed very verbose, and some can contain a lot of nuance in just a few words. my goal in this table wasn’t to argue that, but to show how much information we can convey/understand within a minute. regardless of the language, the OOM is probably correct. even world record holders are only producing 650 WPM, and reading (skimming) 2000 WPM (with ~50% reading comprehension).
let’s convert WPM to bits/second to make this concrete. assuming 1 word ≃ 6 bytes (5 letters + space) in ASCII (1 byte/char → 48 bits/word):
$\text{bits/s} = \frac{\text{WPM} \times 48}{60} = 0.8 \times \text{WPM}$
| Metric | Q1 bits/s | Median bits/s | Q3 bits/s |
|---|---|---|---|
| Typing speed (computer keyboard) | 28 | 34.4 | 40.8 |
| Typing speed (professional typists) | 49.2 | 70 | 96 |
| Stenotype typing speed | 88 | 288 | 288 |
| Handwriting speed (adult) | 7.2 | 10.4 | 16 |
| Handwriting speed (shorthand) | 280 | 280 | 280 |
| Morse code speed (manual) | 16 | 16 | 56 |
| Morse code speed (typewriter) | 60.5 | 60.5 | 60.5 |
| Silent reading (non-fiction) | 164.8 | 190.4 | 215.2 |
| Silent reading (fiction) | 184 | 208 | 232 |
| Subvocalization | 170.4 | 180 | 190.4 |
| Auditory reading | 330.4 | 340 | 350.4 |
| Visual reading | 410.4 | 460 | 510.4 |
| Reading aloud (17 langs) | 147.2 | 147.2 | 188 |
| Audiobook narration speed | 120–128 | 124 | 128 |
| Slide presentation speed | 80 | 90 | 100 |
| Auctioneer speaking speed | 200 | 200 | 200 |
| Fastest recorded speaking | 489.2 | 509.6 | 509.6 |
voice
I do think voice is under-indexed today. Today 95% of interaction is text [typing] but … I think voice will be a lot bigger going forward.
— Zuck on stage at LlamaCon [April 2025]
that table above highlighted reading speeds as well as speaking speeds. reading aloud in 17 languages averages between 155-213 WPM, which we can use as a rough benchmark for normal speech communication rate. audiobook narration has been studied for balancing clarity and engagement, and suggests maintaining a standard speed of 150-160 WPM. slide presentations/ted talks are slowed to 100-125 WPM to ensure audience comprehension.
note how that’s 4-5x more than the ~43 WPM we type on the computer. it’s no wonder that adoption for voice tech has taken off recently. it’s just easier to communicate by voice. we evolved that way, trading myths and folklore orally for tens of thousands of years. but writing has its own merited use cases. writing gives you more time to think, to be intentional. voice requires interpretability, which has only recently been unlocked.
how much information does that convey? can we measure this? will that vary across languages?
the speed of sound
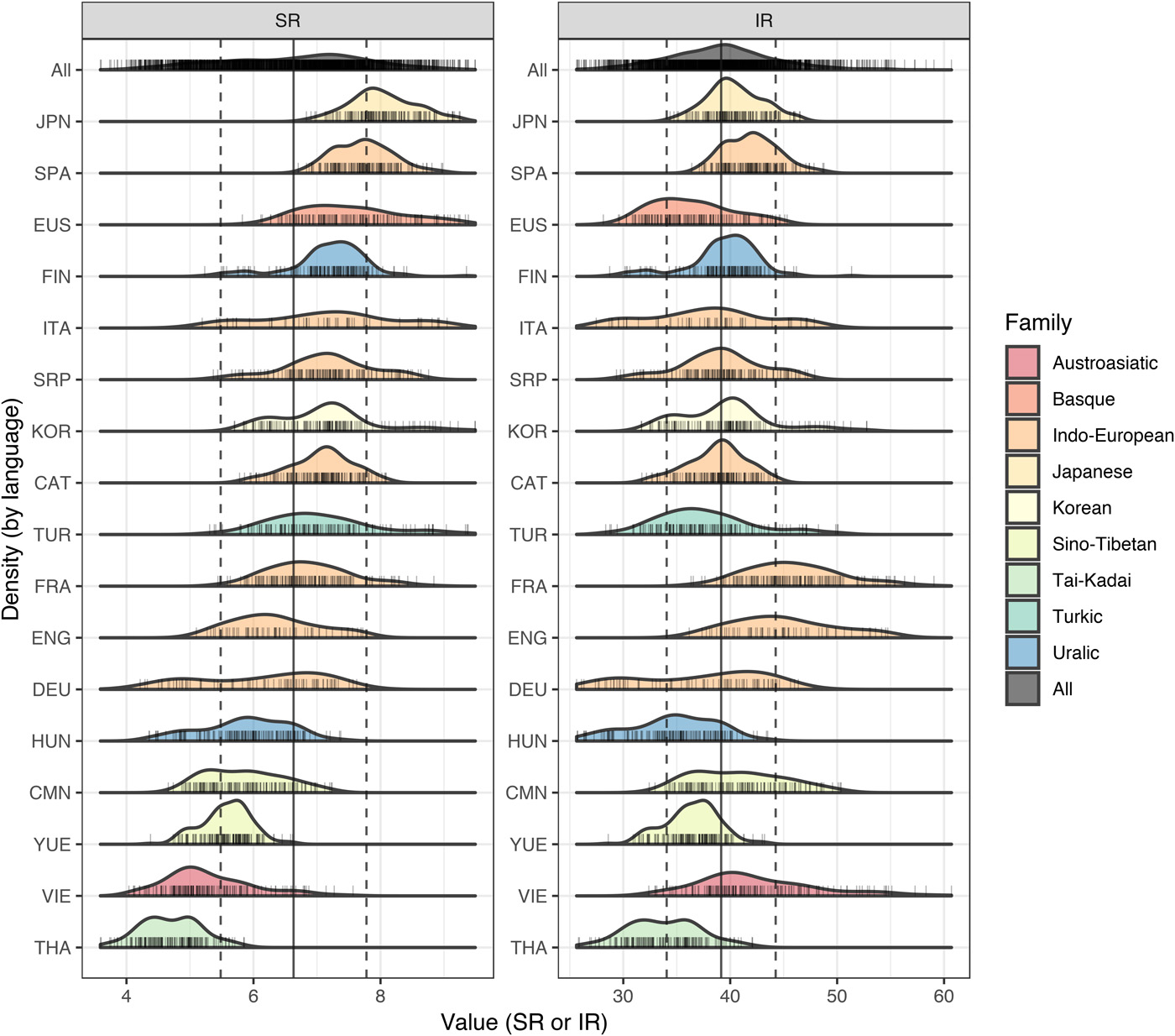
Figure: Language transmission speed comparison.
research shows that despite the differences in languages, they all convey information at about 39.15 bits per second. this means human languages are actually very similarly efficient at sharing information, no matter how they sound or are structured.
across 17 different languages the researchers found that languages inherently balance how much information is in each syllable with how fast we speak to keep communication effective. japanese speakers talk fast but pack less information per syllable. vietnamese speakers talk slower but each syllable carries more semantic weight. mandarin uses tones to multiply meaning; spanish uses more syllables to achieve the same effect. the throughput converges to ~39 bits/sec.
they suggest that languages may have evolved to fit our brain and body capabilities. tbh i think this is a bit of a stretch and gives me humanist sapir whorf vibes but they prob know more about this stuff i do lol.
but is that the limit?
39.15 bits isn’t a lot of information encoding, especially by modern file exchange standards. in 2005, internet bandwidth became capable of data transfers at ~2 megabits per second (2,000,000 bits), which enabled YouTube to stream video. this is a 51,082× increase in raw bit-rate capacity. nowadays, average broadband connections yield ≈95.1 Mbps, so multiply by another 100x. but if you’re a pro gamer, or have the purchasing power to pay a whopping $50/month, you can get 1Gbps.
side note, but some cal tech folks recently came out with a journal article with the banger title: The unbearable slowness of being. :slowclap: their argument was that its not even truly 39bits/s because a lot of it is ‘noise’. the actual ‘effective’ information thruput is actually ~10bits/s.
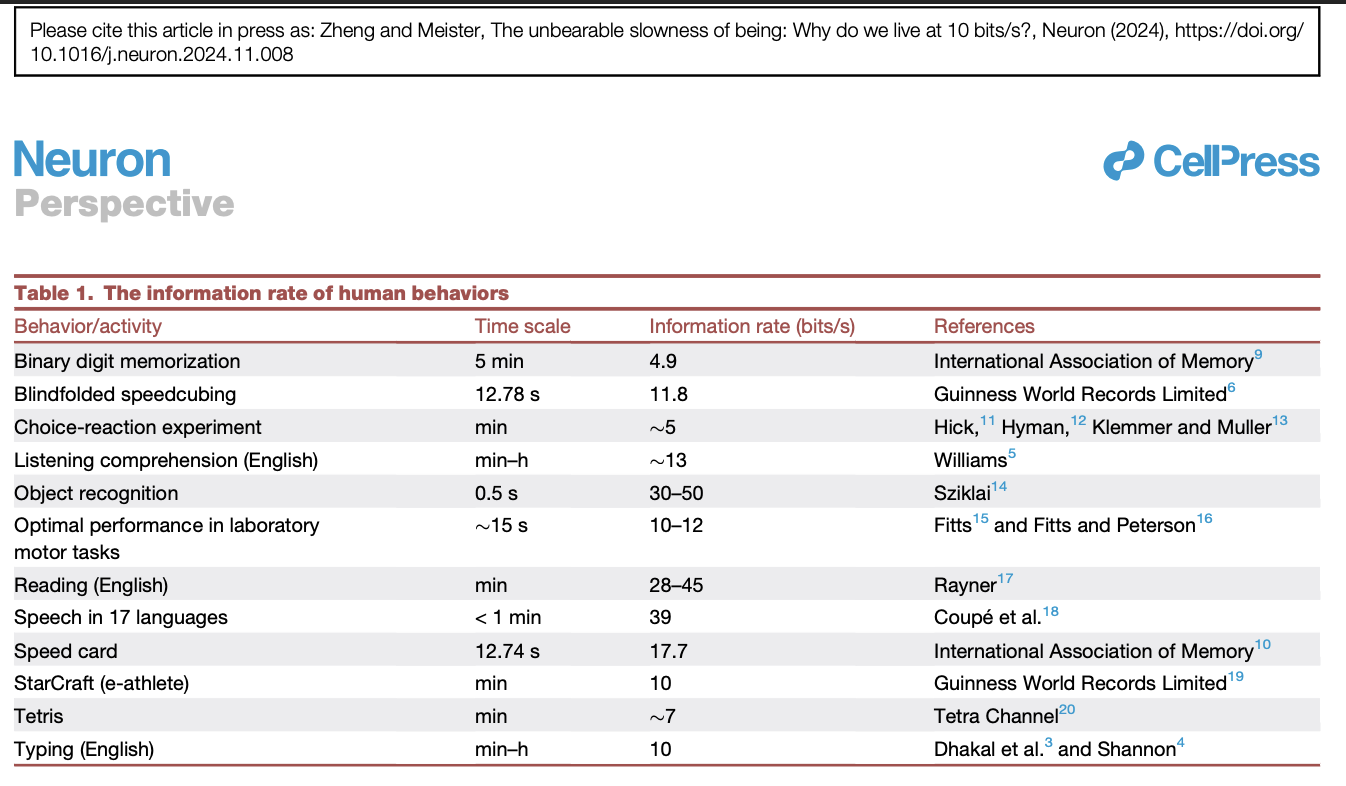
Figure: other information transmission speed comparisons.
all this is great info about the human biological contraints but what about the functionality of the actual mediums in which we ingress and egress voice/text packets?
the long wait for voice
It was a year prior to the aforementioned iOS 6 that Apple first introduced the idea of an assistant in the guise of Siri; for the first time you could (theoretically) compute by voice. It didn’t work very well at first (arguably it still doesn’t), but the implications for computing generally and Google specifically were profound: voice interaction both expanded where computing could be done, from situations in which you could devote your eyes and hands to your device to effectively everywhere, even as it constrained what you could do.
— Ben Thompson, Google and the Limits of Strategy (2016)
voice assistants have been a pipe dream for a long time. it may finally be around the corner. Speech-to-text (STT) models are getting below 5% WER, meaning dictation to siri, alexa, and chatgpt are nearly perfect. once you add on LLMs, even the slight mistakes can be course corrected in post transcription processing given sufficient context (known in the industry as APE).
and sure enough, voice search queries are indeed typically longer, with an average length of 29 words. pair that with the information that 46% of all Google searches are seeking local information, 76% for voice searches. most of the 8.4 billion active voice assistant devices are locally searching for:
| Sector | Voice Search Users In US |
|---|---|
| Weather | 75% |
| Music | 71% |
| News | 64% |
| Entertainment | 62% |
| Retail | 54% |
| Food delivery and restaurants | 52% |
| Sales, deals and promotion | 52% |
| Healthcare and wellness | 51% |
| Consumer packaged food | 49% |
| Local services | 49% |
| Personalized tips and information | 48% |
| Making a reservation | 47% |
| Fitness | 46% |
| Fashion | 45% |
| Travel | 43% |
| Upcoming events or activities | 42% |
| Finance | 42% |
| Other | 42% |
| Store location and hours info | 39% |
| Access to customer support or service | 38% |
Source: BrightLocal, Think with Google, Oberlo
now take each of these, ask for a purple logo from midjourney and make rage bait on the internet like all of the newly minted YC companies clammoring on X (the everything app) harbinging the chasm precipise crossing.
beyond words
note that voice is not only more verbose it also carries significantly more paralinguistic information — prosodic features like pitch, cadence, as well as temporal dynamics that encode sentiment, sarcasm, and intent. text lacks this entirely /s.
i’m not sure how much needs to be explicitly measured. like you could do some supervised sentiment analysis classification algorithms, or you could have it be intuited by the omni models. more and more so, as we scale ad infinitum, i’m willing to take the bitter lesson and let the neural nets learn sarcasm independently. same has applied to fluid dynamics simulations, chess engine moves and image segmentation. if ur curious how they learned these world models, you can always do ablation probing on the conjectures implied by NN models. tbh i think we should solve physics this way more generally; instead of trying to armchair mathematical proofs, we learn the underlying manifold that the NN discovered.
small aside but why haven’t brands fully exploited multimodal AI for shoppable video and voice shopping? despite AR/VR growth, voice-first commerce remains <1% of e-commerce spend … probably bc it hasnt been ‘good enough’. i wouldnt be surprised to see a boon of this in late 2025. the frontier for “ask and buy” agentic experiences in headsets and smart speakers are very very feasible. u read more of this rant in my 125pg schizofesto lol
image
The information bandwidth of human vision is over 1 million times higher than the bandwidth of reading or listening to language.
product designers take advantage of this with carefully crafted visual interfaces that efficiently convey complex information and help users take action on it.
say you want to compare restaurant options. a scrollable map with pins, photo overlays, and filter buttons will be more effective than typing criteria into a chat interface and reading results one at a time. some interfaces are just better suited to certain tasks.
google lens handles 20+ billion visual searches per month. the camera is becoming the primary search interface for physical-world queries. typing “blue ceramic vase with gold trim, art deco style, approximately 12 inches” is much harder than pointing your phone at the vase and asking “where can i buy this?”
google search with Lens is seeing increasing usage — the camera is becoming a query interface.

Figure: AI Shopping market map.
im not surprised theres a bunch of yc startups wrapping around google lens either.
LeCun’s bandwidth argument
Yann LeCun (personality hire at meta) had made the same overarching thesis on X (the everything app):
Language is low bandwidth: less than 12 bytes/second. A person can read 270 words/minute, or 4.5 words/second, which is 12 bytes/s (assuming 2 bytes per token and 0.75 words per token). A modern LLM is typically trained with 1×10¹³ two-byte tokens, which is 2×10¹³ bytes. This would take about 100,000 years for a person to read (at 12 hours a day). this is roughly equiv to the bitrate the caltech folks found a few paragraphs ago so math checks out - or its at least in the same oOM.
Vision is much higher bandwidth: about 20MB/s. Each of the two optical nerves has 1 million nerve fibers, each carrying about 10 bytes per second. A 4-year-old child has been awake a total of 16,000 hours, which translates into 1×10¹⁵ bytes.
in other words:
- visual perception bandwidth is 16 million times higher than language.
- in 4 years, a child sees 50× more data than the biggest LLMs trained on all public internet text.
sundar says google search via lens is increasing in usage (65% YoY, now 100B searches). instead of typing “what kind of tree has these leaves”, take a photo. instead of describing a bug, point your camera at it. for 25 years, search meant typing words. now search increasingly means pointing a camera. chat does this well too. the limits of language are evident when describing the religious rapture of a acid trip, as u probably know dear reader.
most human knowledge comes from sensory experience of the physical world. language is the icing on the cake. there’s no way we reach human-level AI without machines learning from high-bandwidth sensory inputs. yes, humans can get smart without vision. even without audition. but prob not without touch. touch is high bandwidth too and we have no good way to digitize it yet. maybe the optimus hand and a haptic glove. maybe we can tap the neurons directly. still a ways away.
in the meanwhile, be my eyes is a clever way to integrate data collect/ray-bans style ‘see what you see’ but for a good cause: they help blind ppl navigate. recently they integrated GPT-4V for instant, 24/7 visual assistance.
thought
the brain is a bottleneck.
this may be unintuitive for the uninitiated. we think of our brains as powerful — and they are, in certain ways. but when it comes to sequential processing, they’re shockingly slow. people know that listening to 120% speed audio doesn’t hinder understanding, so the bottleneck isn’t the “listening” part, it’s the L3 cache malloc.
your sensory systems can intake ~millions of bits per second (Koch et al., 2006). your brain compresses this to ~10 bits of conscious experience. that’s a million-fold compression from sensation to thought. ofc a lot is redundant, ignorable, or static but still rlly impressive.
reading the cached thoughts of fedora raidboss and famously stinky Eliezer Yudkowsky:
One of the single greatest puzzles about the human brain is how the damn thing works at all when most neurons fire 10–20 times per second, or 200Hz tops. In neurology, the “hundred-step rule” is that any postulated operation has to complete in at most 100 sequential steps—you can postulate as much parallelism as you like, but you can’t postulate more than 100 (preferably fewer) neural spikes one after the other.
Can you imagine having to program using 100Hz CPUs, no matter how many of them you had? You’d also need a hundred billion processors just to get anything done in realtime.
If you did need to write realtime programs for a hundred billion 100Hz processors, one trick you’d use as heavily as possible is caching. That’s when you store the results of previous operations and look them up next time, instead of recomputing them from scratch. And it’s a very neural idiom—recognition, association, completing the pattern.
It’s a good guess that the actual majority of human cognition consists of cache lookups.
this is why learning is slow but recognition is fast. why experts just know the answer. why interfaces that leverage cached patterns (icons, familiar layouts, consistent gestures) are faster than novel ones. in the industry they call em dark patterns.
great interfaces feel “fast” even when objectively slow bc they match human cognitive bandwidth. AIs that dump walls of text feel overwhelming bc they exceed it. watching GPT-4 stream at 50+ tokens/second (or wahtever FAL is boasting these days) when you can only process ~4 words/second creates cognitive dissonance.
lets go deeper into this superhuman rabbit hole.
machine communication
| System | Information Rate |
|---|---|
| Human conscious thought | ~10 bits/s |
| Human language | ~40 bits/s |
| Human vision (optic nerve) | ~10 megabits/s |
| Ethernet (home) | ~100 megabits/s |
| Datacenter NVLink | ~400 gigabits/s |
| Fiber optic (record) | ~400 terabits/s |
if human communication is stuck at 39.15 bits/second, what about machines?
we can get to some serious bitrates without the constraint of network packet switching. Machine-to-machine (M2M) links at data centers like Elon’s Colossus Supercluster today can now get to 400 GB/s, with 800 GB/s rolling out across the country. by 2030, 1.6 TbE (1.6 TB/s) is expected to predominate for server-to-server traffic.
how fast will broadband traffic get? the world record on a single fiber optic cable is 402 TbE.
the speed of light
to put the scale of human communication in perspective: the world record for data transmission on a single fiber optic cable is, again, 402 TERABITS per second. compared to the 39.15 BITS per second throughput of human language, a single cable can transmit information over 10 trillion times faster than a person can communicate with words:
$\frac{402 \times 10^{12}}{39.15} \approx 1.03 \times 10^{13}$
how many human lifetimes of speech fit into one second of modern fiber? let’s do the math:
- Average human verbal communication rate: 39.15 bits per second
- Generously assume a human yaps for 16 hours/day, 365 days/year, for 80 years:
- $16 \times 60 \times 60 = 57,600$ seconds/day
- $57,600 \times 365 = 21,024,000$ seconds/year
- $21,024,000 \times 80 = 1,681,920,000$ seconds/lifetime
-
$1,681,920,000 \times 39.15 \approx 65,852,688,000$ bits per lifetime
-
Modern fiber optic cable: 402 terabits/second = 402,000,000,000,000 bits/second
-
Number of lifetimes in one second:
- $\frac{402,000,000,000,000}{65,852,688,000} \approx 6,105,000$ lifetimes
so, in just one second, a single fiber optic cable could transmit the entire spoken output of over 6 million human lifetimes. funnily enough, thats roughly how many people die every ~~second~~ (5 weeks) around the world. maybe thats why ur life flashes before your eyes at the pearly gates, its just saving the simulation checkpoint.
meanwhile, LLMs generate tokens faster than humans can read:
| Model | Tokens/sec | Tokens/min | MB/min |
|---|---|---|---|
| GPT-3 | ~11,300 | ~678,000 | ~21.7 |
| Llama 2 7B | 1,200 | 72,000 | ~2.3 |
| DeepSeek R1 | 100 | 6,000 | ~0.2 |
| Llama 4 8B | ~2,500 | ~150,000 | ~4.8 |
| GPT-4o | ~5,000 | ~300,000 | ~9.6 |
| DeepSeek V2 | ~300 | ~18,000 | ~0.6 |
even the “slow” models are outputting orders of magnitude more than humans can process. this is the fundamental mismatch between the speed of our thoughts, the speed of our words, and the speed of our machines.
the display is the bottleneck now, not the model. and when AI agents talk to each other? they dont have to use tokens at all, they’ll pass activations directly and preserve perfect information. we become reviewers rather than participants in the conversation.
the future of communication will be defined by how we bridge this gap.
intent translation
one of my goals is to find an evergreen problem.
there will always exist a problem of communicating the thoughts in my head. we tried to solve this by codifying a set of words that symbolize meaning, but it has limited us to 39.15 bps. an image is worth a thousand words. how many images can we see in a minute? how many words would that equate to? how can we go past this limit?
CEO and technoking Mark Zuckerberg has mentioned it on calls, multiple times — tbh like basically every call:
We certainly want to make sure that video on Facebook is healthy, we think video is going to be increasingly how people communicate and consume information
ofc hes tryna feed u ads and ai slop engagement bait but the underlying point is the same.
the moonshot
Neuralink is an extrapolation of this line of thought (pun not intended, but now im intending it). it’s probably not something that we can build upon in 2025, but it’s certainly a moonshot worth pursuing. our fleshy brains are probably incapable of the token/information throughput of LLM models, so AIs will always be capable of more ‘intelligence’. the question is whether we’ll partner with them effectively.
in a way we have started to do ‘cognitive offloading’ to google for a while now. it wouldnt surprise me if I could send a brain query to the neuralink cloud cluster and have it respond with a compressed answer.
additionally, there is some pretty well-documented work on decoding imagined speech into synthesized words, as well as brain-to-image reconstruction research that can visually re-create what someone is ‘seeing’ or imagining. not to mention the milestone progress of cochlear implants restoring hearing and brain-computer interfaces aiding in motor function recovery.
without getting too lost in the future’s uncertainty, what we can be certain about is that current AI agents are being increasingly implemented in enterprise use cases. there has been a lot of work done on the GEO for AIO, indexability/retrievability of information, and risk mitigation of AI outputs. what has been lacking, though, is the advent of better ways to communicate my expected output from the model.
this requires clarity from the human inputter. it’s just a hunch, but something worth solving for.
financial thesis translation
llama prompt optimization
socratic dialogue
most people don’t know what they want until they see what they don’t want. that’s the classic product design problem. the same applies to AI interactions. this is why prompt engineering exists as a skill — not because models are bad, but because translating human intent into machine-actionable instructions is genuinely hard. the quality of an output can only be as good as its input, the adage goes.
Models will eventually intercommunicate directly through latent representations, similar to how the hundreds of different layers in a neural network in GPT-4 already interact. so u can fathom approximately no miscommunication, ever again. no translation loss. gbye tower of babel, we did it. smite me (dont actually plz)
unlike humans, these models can amalgamate their learnings across all their copies. so one AI is basically learning how to do every single job in the world. AI firms will look from the outside like a unified intelligence that can instantly propagate ideas across the organization, preserving their full fidelity and context. every bit of tacit knowledge from millions of copies gets perfectly preserved, shared, and given due consideration.
humanity’s great advantage has been social learning, the ability to pass knowledge across generations and build upon it. but human social learning has its limitations: biological brains don’t allow information to be copy-pasted. so you need to spend years (and in many cases K-12+) teaching people what they need to know in order to do their job. the top achievers in field after field are getting older and older, it just takes longer to reach the frontier of accumulated knowledge. the AIs with self-play are hitting those frontiers in a few GPU months.
but language goes beyond just “transferring information” or “expressing ourselves.” it should be understand as a tool for coordination. when you prompt an AI, you’re not transferring complete specifications, you’re coordinating toward a shared goal. the best AI interfaces facilitate coordination rather than demanding specification (eg cursor). but we need to be able to express those goals clearly, and its unbearably slow.
wearables and ambient AI
the next interface shift is underway. project astra, live AI, smart glasses — the first wave of ambient computing.
google’s project astra and android XR point toward AI that sees what you see, hears what you hear, responds in context. meta’s live AI on ray-ban glasses already offers real-time translation, object identification, contextual assistance. that context will get stored and behaviors will be reinforced.
these aren’t just new form factors. they represent a fundamental shift:
| Era | Interface | Cognitive Load |
|---|---|---|
| CLI | Type exact commands | High |
| GUI | Click through menus | Medium |
| Mobile | Touch and swipe | Low-medium |
| Voice | Speak naturally | Low |
| Ambient | Just exist | Near-zero |
the form factor that wins will be the one that disappears. this is why glasses are the leading candidate — already socially normalized, no hand movement required, direct line of sight.
| Device | Form Factor | Status | Key Capability |
|---|---|---|---|
| Ray-Ban Meta | Glasses | Shipping | Camera + audio + AI |
| Google + Warby Parker | Glasses | Announced | Gemini integration |
| Jony Ive + OpenAI | Unknown | Announced | AI-native design |
| Apple Vision Pro | Headset | Shipping | Mixed reality |
| Humane AI Pin | Chest pin | Struggled | Projector + AI |
| Rabbit R1 | Handheld | Struggling | LAM concept |
| Limitless | Pendant | Shipping | Meeting memory |
| Friend | Pendant | Early | AI companion |
| Bee | pendant | early | memory/notes |
meta is spending $20B+ per year on Reality Labs. google partnered with Warby Parker for fashion credibility after Glass failed. Jony Ive joining OpenAI signals design will matter as much as AI capability.
the interface is becoming invisible. from punch cards to GUIs to touch to voice to… just being. the interface will become ambient and queries will become implicit: instead of “hey siri, what’s on my calendar,” the AI notices you looking at your watch and says “you have 15 minutes before your next meeting”, like your EA or attentive wife would. the above companies accumulate context continuously so that the “queryable day” vision can actualize “what did we decide about the color in that meeting?” into a coherent response. unfortunately, privacy dissapears; everything recorded by default, either done yourself or with the abundant devices around you. consent and candid conversations died in the belle epoque of the 2000s.
google glass failed partly because people found it socially unacceptable. will ray-bans succeed? zuck prioritizes this as the #1 requirements (which is why it partnered with the social clout of eyewear brands). early signs lean yes.
conclusion
we started with McLuhan: “All media are extensions of some human faculty.” the interface is an extension of thought into the world. but extensions have limits.
the fundamental constraint hasn’t changed in 100,000 years: ~39.15 bits per second. that’s what we can communicate through language, no matter how fast we type or how clearly we speak. languages evolved to this (physical) ceiling and isnt gonna grow much beyond that in the coming years.
voice gives us 4-5x more bandwidth than typin, but still bounded by language games. vision gives us 16 million times more bandwidth than language, but we can’t output through our eyes (yet?). our brains process trillions of operations per second but can only serialize ~10 bits of coherent thought per second. meanwhile, machines talk to each other at terabits per second. the gap is only widening.
intent translation is the central problem. getting what’s in your head into the machine. every interface innovation: from writing to printing to the internet to voice to vision, has been an attempt to make this translation more efficient. we’re not there yet.
but we’re closer than ever:
- speech-to-text below 5% error
- multimodal models that see, hear, and reason
- memory systems that accumulate context over time
- wearables that provide ambient context without explicit queries
- socratic interfaces that help articulate what you can’t yet express
the near-term future is voice as the primary input for casual queries (finally works well enough), vision as context for AI assistants (they see what you see), wearables as the form factor that makes this ambient, memory as the moat that makes personal AI sticky, socratic interfaces that help you articulate what you can’t yet express.
the medium-term future might be latent space communication & bartering between advocate AI agents (no human language in the loop), and AI organizations that operate at machine speed with human oversight. the longterm vision is to have neural interfaces that bypass language entirely (decades away).
the interface is becoming invisible. that’s progress. but invisibility isn’t the same as absence. someone will build the infrastructure for ambient AI, for intent translation, for agent coordination.
its not about making humans faster. that has never ended well. its about making machines better partners despite our limitations. there is a fundamental mismatch between the speed of our thoughts and the speed of our machines. the future of communication will be defined by how we bridge this gap.
the limits of our interface are the limits of our world. lets expand them.
if you’re building in this space — wearables, bci, agent infrastructure, intent translation, memory systems — reach out: vincent [at] vincent . net
appendix: the exponential history (and future) of bandwidth
ok so if you’re still reading, you’re probably the type to want the full picture. the stuff above focused on the human bottleneck but let me nerd out on the machine side of things for a sec — how fast has telecommunications actually grown, and where is it going?
200 years of bit rates
futuretimeline.net compiled a pretty sick timeline of telecommunications bit rates from 1798 to projections out to 2120. here’s the speedrun:
| Year | Technology | Bit Rate |
|---|---|---|
| 1798 | Optical telegraph (Claude Chappe’s semaphore) | ~0.4 b/s |
| 1840s | Electrical telegraph (Morse code) | ~100 b/s |
| 1876 | Telephone (Alexander Graham Bell) | 64 kb/s |
| 1940s | B&W television (NTSC, 525 lines) | 26 Mb/s |
| 1950s | Color NTSC (added RGB channels) | ~78 Mb/s |
| 1990 | HDTV 720p | 1.3 Gb/s |
| 2010 | Ultra-HDTV 4K (2160p) | 12.7 Gb/s |
| 2020 | 8K (4320p) | 47.8 Gb/s |
{kind=link}
look at those jumps. from semaphore flags at 0.4 bits per second to 8K video at 47.8 billion bits per second. thats a 100-billion-fold increase in ~220 years. and the curve isn’t slowing down.
internet speed: 14.4 kbps to terabits
the global average internet connection speed has been on its own exponential tear. per futuretimeline and Cisco data:
| Year | Global Avg Speed | What It Enabled |
|---|---|---|
| 1991 | 14.4 kbit/s | static HTML, a handful of pages |
| 1995 | 24 kbps | early search engines, Amazon/eBay launch |
| 2000 | 127 kbps | dot-com boom (and bust) |
| 2005 | ~1 Mbit/s | broadband era, video streaming begins |
| 2010 | ~10 Mbit/s | social media, HD video |
| 2017 | 39 Mbit/s | mainstream streaming (Netflix etc.) |
| 2022 | ~100 Mbit/s | remote work, 4K streaming |
| 2030s (projected) | ~1 Gbit/s | 16K video, real-time holographics |
| 2040s (projected) | >10 Gbit/s | multiview displays, volumetric content |
| 2050 (projected) | tens of Gbit/s | probably stuff we cant even fathom rn |
growing at ~20% per year with a huge gulf between nations (Singapore at ~300 Mbit/s vs Turkmenistan at 4.3 Mbit/s). 50+ countries already offer 1 Gbit/s consumer plans. early adopters in advanced nations will hit terabit speeds in the coming years — 1,000x faster than gigabit, a million times faster than the megabit connections most of us grew up with.
the display technology roadmap
this is where it gets wild. Pierre-Alexandre Blanche (University of Arizona) published a paper in Light: Advanced Manufacturing projecting the milestones for display tech based on the long-term telecom bit rate trend:
| Era | Technology | Required Bit Rate | Description |
|---|---|---|---|
| 2020s | 8K | 47.8 Gb/s | current bleeding edge consumer displays |
| 2030s | 16K | ~hundreds of Gb/s | probably overkill for most ppl but we said that about 4K too |
| ~2050 | Multiview (HPO) | — | motion parallax reproduced smoothly as viewer moves. horizontal only tho |
| ~2065 | Volumetric 4K | 1.3×10¹³ b/s | pixels → voxels. the screen gets a z-axis. fully 3D content in 4K. ~1000x more data than 2D |
| ~2085 | Light field (full parallax) | ~10¹⁴ b/s | both horizontal AND vertical parallax. multiple users at varying positions |
| ~2115 | True holography | 3×10¹⁵ b/s | literally perfect display. all optical cues rendered. blade runner 2049 “Joi” type stuff |
from pixels to voxels. from 2D to volumetric. from flat screens to holograms projected into your living room. each step requires roughly an order of magnitude more bandwidth than the last. and if the 200-year trend holds… we’ll get there.
so what does this mean for the bottleneck?
here’s the punchline: machine bandwidth is scaling exponentially. human bandwidth is not. we’ve gone from 0.4 b/s (semaphore) to 402 Tb/s (fiber) on the machine side, a 10^15 improvement. on the human side we’ve gone from… grunts to language. maybe a 10x improvement over 2 million years. generous.
the gap between what machines can transmit and what humans can process is widening by orders of magnitude every decade. this is the reason why intent translation matters so much. its not that we lack bandwidth to move information around — we have absurd, incomprehensible amounts of it. we lack bandwidth to move information in and out of human brains.
by 2065, when we might have volumetric 4K displays beaming voxels at 13 terabits per second, we’ll still be stuck processing ~10 bits per second of conscious thought. the display will be 1.3 trillion times faster than the viewer. lol.
until neuralink (or something like it) cracks open the skull bottleneck, the interface layer — the translation between human intent and machine capability — will remain the most important unsolved problem in computing. maybe in all of human coordination. no pressure.
Sources: FutureTimeline - Internet Speed Predictions, FutureTimeline - Telecommunications Bit Rates, Blanche 2021 - Holography and the future of 3D display, Cisco VNI Reports